
Scraping XDA Forums
A while back I was looking for a solution to a problem I was having with installing a specific Magisk Module to my Android phone. I'm pretty n00b at Android rooting and I was having a hard time looking for solutions on XDA Forums, which is when I had the idea of building a RAG chatbot for XDA Forums. This meant I would have to obtain all of the posts on the forum. In the end, I ended up scraping about 6M pages and 68M posts off the forum and found a security vulnerability in the API. In this post, I will go over how I did it and what I learned in the process.
Stage 1: Basic HTML Scrape with SQLite
I couldn't find any docs on an API for the forum, so I decided to go with parsing the raw HTML. I used sqlite since I heard it's pretty easy to use from within Bun.js. I obtained the links to the threads I would have to scrape through the /sitemap.xml file that is used by web crawlers for SEO. Xenforo, the forum software used by XDA, does remove some of the threads from the sitemap, but this wasn't a problem since a majority of the threads were indexed.
Before I get into the details, it's important to talk about some of the terminology of this forum. XenForo refers to a singular comment from a user as a post. A thread is a collection of posts stringed together in a conversation. Each thread has a starting post that asks a question, releases a new ROM, links an article, or something else, and underneath it users can discuss the topic of the thread with posts.
My initial implementation was pretty simple.
- Fetch in loop with exponential backoff (to avoid rate limiting)
- Extract data using
jsdom - Insert data into SQLite
- Repeat for next thread URL after 1 second wait period
All of this ran in 10 processes each with 10 concurrent tasks at a time.
I'll be honest, bun:sqlite's DX was really impressive, I loved how I could type a tuple for the inputs and have that appear in the arguments when executing the query:
const threadTagsInsertQuery = db.query<any, [thread_id: number, tag_id: number]>(
`INSERT INTO threadtags (thread_id, tag_id) VALUES (?, ?)`,
);
threadTagsInsertQuery.run(id, tagId);I had an issue though, SQLite wasn't able to handle the large amount of data I would through at it. I was running multiple workers that would run through different slots of the sitemap entries, and a lot of the transactions were clashing with each other since they were all trying to write to the same table. I tried using WAL Mode and other options, but at the end of the day SQLite is optimized for read-and-writes not for a write-heavy workload.
Stage 2: Switch to Redis
In my case I really didn't need a relational database to index the content for me, so I decided to go with a simple KV, Redis. Redis turned out to be much faster. However, I ran into a problem, Redis stores the entire KV in memory since it's trying to optimize for reads. This filled up my RAM fast after I hit around 500,000 threads w/ just the metadata. In my case I didn't want to conduct any read operations at my KV, I just wanted to throw data at it and have it be read-optimized at a later point in time.
I also switched from jsdom to linkedom because jsdom apparently does some form of emulating the browser environment to get really good accuracy, which meant it consumes a large amount of memory an processing time. Linkedom wasn't great at supporting edge cases, but I was able to get it working with some workarounds. There were many inconsistencies for the selector paths I would have to use for querying the DOM, so I had a failure snapshot folder which would throw in all my errors mid-process and skip those threads. This let me iteratively add support for threads which I didn't support as of yet, such as article threads.
I left my scraping script running overnight and I woke up to the following:
- I was IP Banned from XDA Forums and XDA Developers.
- I accidentally overwrote the page data:
-export async function insertPage(page: Page) {
+// i put the pageNumber as the key
+// :( 😭 😭 😭
+export async function insertPage(page: Page, threadId: number) {
await redis.hset(
"my_hash",
- `thread:page:${page.pageNumber}`,
+ `thread:page:${threadId}:${page.pageNumber}`,
JSON.stringify(page)
);
}For a few weeks it seemed as if all was lost, I tried to see if I could use redundant data from other keys to recover the page keys, but that wasn't a possibility, until I found out that XDA Forums has an Android app...
Stage 3: Android App API and finding security vulns
I initially found out about the Android App API through @theimpulson's community Android App, ReLab (no longer maintained unfortunately).
It seems as if the Android App uses OAuth endpoints implemented in a Xenforo extension, to authenticate users and provide them with a token they can use.
Interestingly, the Android API doesn't authenticate users to ensure that they have a token, meaning I can make API requests without a token. The Android API wasn't part of the IP ban either, so I could use this to refetch the data for the scrape.
I rewrote my initial scraping script to instead use the Android API and began fetching threads. In the middle, I ran into a few bugs with the Android API processing certain posts and returning an empty string. It started off infrequently, but became more and more common in a certain date range of the older threads, probably caused by a bug in the Android API.
This is when I realized that the implementation of the Android API meant that I could also access a slightly different Web API by changing the user agent, and passing in an authentication token. Original XenForo documentation states that I would need an Admin API key, but XDA Forums must be configured differently to allow users to use the API with their own scopes. This Web API didn't run into any of these bugs and gave me the correct posts and metadata for the rest of the threads (Note: A lot of this has since changed upon reporting these vulnerabilties to the XDA Forums moderators).
Stage 4: Redis to RocksDB
As the script was running in the background, I searched for a solution to Redis' memory problem. According to one article I found, Redis does have a Redis on Flash module, but it is underneath a proprietrary license. KeysDB did have a KeysDB on Flash option, but KeysDB was discontinued a few years ago so I didn't want to go with that. DragonflyDB released their Flash feature a few weeks after I was searching for a solution.
Initially, I began writing my own KV by appending keys and values to two separate binary files and sorting the keys manually. While, I was looking for solutions to problems I was running into during implementation, I found RocksDB, which solved the exact issue I had in the first place. RocksDB is a high-performance, KV optimized for fast reads and writes, designed for large-scale data workloads.
RocksDB's official bindings are in C++ and the only N-API bindings used version 6.4, which didn't have the BlobDB feature that I wanted, which would have separated the keys and the values. RocksDB without BlobDB was good enough for me, though, so I stuck with that.
RocksDB was much faster and I ran into no memory issues afterwards. I was able to run the script for a few hours and scrape the entirety of the forum. I couldn't figure out how to set up multi-threading so I wrote to a separate DB for each thread, and then merged in the post-processing stage.
Stage 5: Post-processing
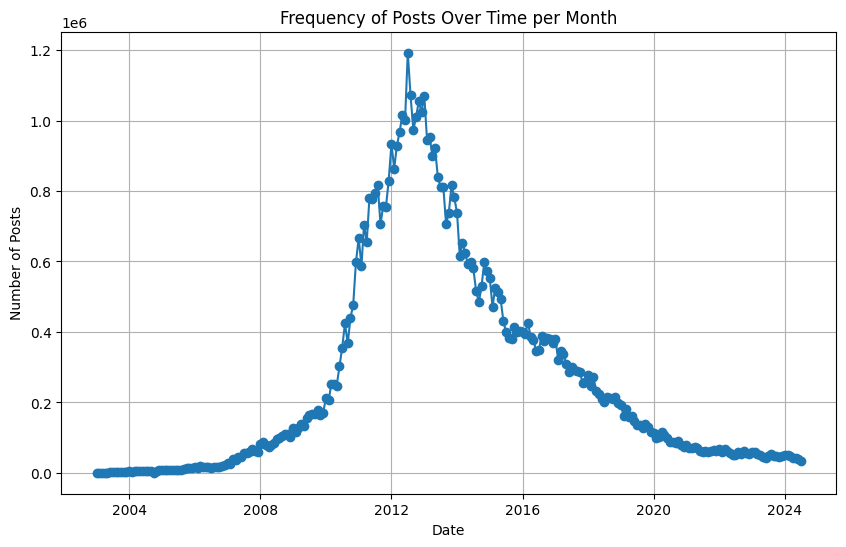
Finally, I had to postprocess the data. I mixed in some of the earlier data from the HTML scrape with the API scrape, since the former had a few more extra fields that I wanted to add in. The final data was about 60GB in size. To do some basic data analysis, I converted it all into a Parquet file and ran some queries on it. Here is an interesting graph showing the activity on the forum over time:
Conclusion
This was a fun project for me, and I got to learn a lot of new tooling and how to manage data at a larger scale. XDA Forums has a wealth of information, and I'll likely be spending a lot of time seeing what I can learn from the scraped data I have. Thanks for reading my blog!